Capstone Project Update #4: The Deadline is Fast Approaching!
Jump to a section in this update
It’s been a little longer than I intended since the last update, and progress on the project has similarly been slow. This is due in part to my facing various challenges in training the MLDriver agents, along with a recent death in my immediate family which has made it rather grueling to keep up with the project.
That being said, the semester soon draws to a close, and even with a graciously given extension from my professor, I would very much like to graduate on time and finish what I started. Let’s see where I’m at and what I can realistically accomplish for the “final product”.
Conditions for Rewarding the Agents
The key of the reinforcement learning being used to train the agents is determining when they will be rewarded or punished. For example, an ideally trained car would follow the path accurately, stop at traffic signals, and avoid crashing into other carse. As such, we want to reward agents for traversing nodes in the path, and to punish them for colliding with other vehicles and for running through traffic signals. Here’s how that looks in the code:
// Car has flipped upside down
if (Vector3.Angle(transform.up, Vector3.up) > 45f)
{
AddReward(-1f);
EndEpisode();
}
// Car collides with another vehicle
if (carPercepts.CollidedWithObject(out string tag, clear: true))
{
if (tag == "Car" || tag == "TrafficSignal" || tag == "Sidewalk")
{
AddReward(-1f);
EndEpisode();
}
}
// Car violates traffic signal (runs red light or fails to stop at stop sign)
if (carRuleEnforcer.CheckRanTrafficSignal(clear: true))
{
AddReward(-0.5f);
}
// Car drives into the opposite lane
if (pathCrawler.IsInOtherLane())
AddReward(-1f);
}
// Car drives faster than the speed limit
if (carController.velocity > pathCrawler.maxVelocity)
{
AddReward(-0.2f);
}
// Car successfully traverses a node in the path
if (pathCrawler.CheckChangedNodes(clear: true))
{
AddReward(1f);
}
// Punish the car each frame so it is incentivized to continue along the path
AddReward(-0.01f);
The above code snippet is from the overridden function OnActionReceived(). This is run each time the car is given an action from the network (not necessarily every frame, based on the Decision Period parameter for the agent). The code above checks for various conditions to decide whether to reward or punish the agent.
Notice also the AddReward(-0.01f) line at the end. In the absence of this, the agent would likely be able to maximize its reward by sitting still, which is obviously not desirable. As such, we discourage this by punishing the car a small amount each time the network makes a decision.
(Attempting to) Train the Agents
As I slightly feared earlier on in the project, the real challenge has turned out to be the actual training of the driver agents. While the setup of the environments and the code to reward/punish the agents is rather simple, training the agents and tweaking the parameters to facilitate learning can be a rather involved process.
Here’s how the cars are currently performing:
Clearly, this type of driving is not quite up to the standards we want on our virtual roads. The car sits, frantically turning its wheels left and right, accelerating a little bit at a time before immediately braking. Even in lieu of the various other complications that will ultimately be encountered–others cars, traffic signals, turns, etc.–the poor agent just seems… confused.
The current training setup is made up of 16 individual training scenes, each with its own agent training in parallel. In theory, this should speed up the training process, though I still have yet to yield any meaningful learning.

Potential Solutions to Improve Training
With roughly a week to train the agents and submit a completed project, I have limited time to explore fixes for the training. Fortunately, there are a few potential improvements that I can think of, or have briefly explored already.
Imitation Learning
Imitation learning uses a similar approach to reinforcement learning, but instead of the agent starting from scratch and training itself through countless errors, it begins from a known state and tries to imitate a recording. In this case, I would use Unity to record myself driving around for a little while, and train the agent based on that.
I tried this briefly earlier in the project, but I believe other factors made it less effective (errors in reward function, poor performance in the recording, etc.). Having fixed some of these issues, I’d like to give it another crack and see if I can train the agents more effectively and more quickly.
Tweaking Training Hyperparameters
One of the most daunting parts of using ML-Agents (and certainly the most ML-heavy part) is the numerous hyperparemeters that can be provided to change how the training is done. Here’s a look at the hyperparameters I’m currently using:
behaviors:
MLDriver:
trainer_type: ppo
time_horizon: 128
summary_freq: 10000
max_steps: 10.0e5
hyperparameters:
batch_size: 128
beta: 1e-3
buffer_size: 2048
epsilon: 0.2
lambd: 0.99
learning_rate: 3.0e-4
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_epoch: 3
num_layers: 2
vis_encode_type: simple
memory:
memory_size: 256
sequence_length: 64
use_recurrent: false
reward_signals:
extrinsic:
strength: 1.0
gamma: 0.99
Details on the various different parameters can be found at their Github page. Despite the relatively clear descriptions of each hyperparameter, I’ve struggled to tune them to get the learning just right. I’m hoping a Google deep-dive will point me in the right direction to figure it out myself, or find an effective configuration from somebody else.
Training for a Longer Time
Admittedly, I’m not completely sure I’ve even completed a long enough training to get good enough results. I’d thought that a hundred thousand or so iterations would suffice to get the agents to do something, but maybe leaving them for a few hours would be a better indicator of whether the current setup is working at all.
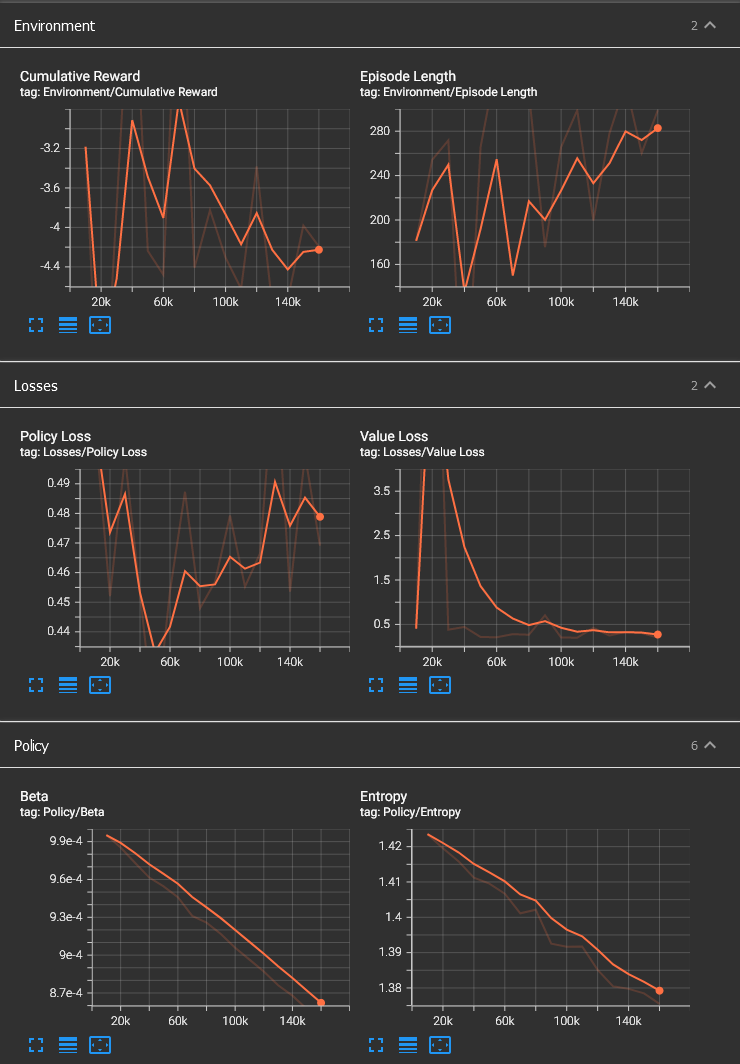
Using the Provided Data Analysis to Find the Problem
TensorBoard enables a developer to easily view the progress of the training, and the many graphs provided can help to give an idea of the effectiveness of the training, and where it may be going wrong. If I do some more thorough investigation into the meaning of each of the values displayed (Value Loss, Beta, Entropy, etc.), I may be able to see what the problem with my training is and fix it.
A Last-Ditch Effort to Submit Something Cool
I’m setting myself up for a pretty intense week or so, even neglecting the rest of my classes (which I don’t really have the option to do). I’m hoping to submit a simulator with somewhat realistic driving capabilities, but I fear facing more of the same troubles this time next week.
In the event that the training doesn’t yield better results, I think I’ll flesh out the hand-written driving logic a bit and ship a product using that instead. Besides, slapping “AI” on a product is pretty widely-practiced in the industry. Perhaps I’ll take it a step further and call the application “Early Access” and give the option to toggle on/off an utterly broken neural-network powered simulation.
Here’s this week’s update of the project schedule, although it’s a little comically cramped at this point.
| february | march | april | may | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Task | Week 1 | Week 2 | Week 3 | Week 4 | Week 1 | Week 2 | Week 3 | Week 4 | Week 1 | Week 2 | Week 3 | Week 4 | Week 1 |
| Simulation Setup | |||||||||||||
| ML-Agents Setup | |||||||||||||
| ML-Agents Training & Testing | |||||||||||||
| Integrate ML-Agents into Simulation | |||||||||||||
| Polish | |||||||||||||
| User Testing | |||||||||||||
| Done! | |||||||||||||